https://leetcode.com/problems/permutations-ii
Permutations II - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
주어진 리스트에 중복된 원소가 있을수도 있는데, 정답리스트에 있는 시퀀스들은 모두 unique해야된단다.
즉 입력리스트가 [1,1,2]면 정답리스트에 [첫번째 1, 두번째1, 2] [두번째 1, 첫번째 1, 2] 이렇게 [1,1,2]가 두 개 나올 수 있는데 이런 중복을 없애라는 것이다. 이유는 모르겠는데 그냥 각 숫자의 개수를 세서 그걸 기반으로 시퀀스를 만들면 될거같다는 느낌이 들었다. 정답도 통과했는데 아직도 이 아이디어가 내 머릿속에서 왜 나왔고 왜 먹힌지 모르겠다. ㅋㅋㅋㅋㅋㅋ
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
counter = Counter(nums)
# Counter()를 사용할 수 없다면 아래 코드를 사용
# counter = {}
# for num in nums:
# if num in counter:
# counter[num] += 1
# else:
# counter[num] = 1
res = []
def dfs(nums, counter, tmp, res):
if len(tmp) == len(nums):
res.append(tmp[:])
return
for num in counter:
if counter[num] != 0:
counter[num] -= 1
tmp.append(num)
dfs(nums, counter, tmp, res)
tmp.pop()
counter[num] += 1
dfs(nums, counter, [], res)
return res
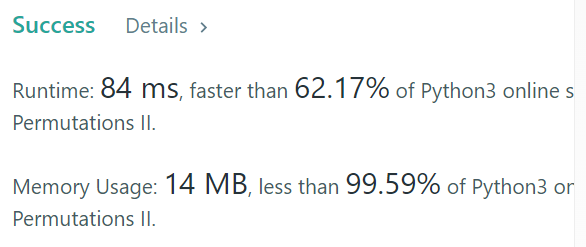
99.59%를 이긴 공간복잡도.. ㄷㄷ
메모리는 result변수 제외하고 counter변수, tmp 변수 외에는 거의 잡아먹질 않으니..
만약 dfs를 호출할 때 dfs(nums, counter, tmp+[num], res)와 같이 tmp에 num을 붙인 새로운 리스트를 복제하는 방법을 썼으면 메모리를 더 많이 먹지 않았을까 ㅋㅋ
'코딩 테스트 및 알고리즘 > leetcode for google' 카테고리의 다른 글
| leetcode : word break 2 (0) | 2022.03.22 |
|---|---|
| leetcode : next-permutation (0) | 2022.03.04 |
| leetcode : Permutations [backtracking] 모든 순열 찾기 (0) | 2022.03.02 |
| leetcode hard : wildcard matching (0) | 2022.03.01 |
| leetcode : decode ways (0) | 2022.03.01 |